OCR(Optical Character Recognition) @OneDrive
Timeline
1 Month (Dec.2024 - Jan. 2025)
Platforms
Web & Mobile
Collaborators
1 Design mentor
4 Developers(2 web, 2 mobile), 2 PMs
My role
Led and executed end-to-end design of OneDrive’s OCR feature across web and mobile, serving 100M+ users. Balanced user needs with technical constraints to ship an MVP in 3 months

THE PROBLEM
“I just want to copy my scanned notes!”
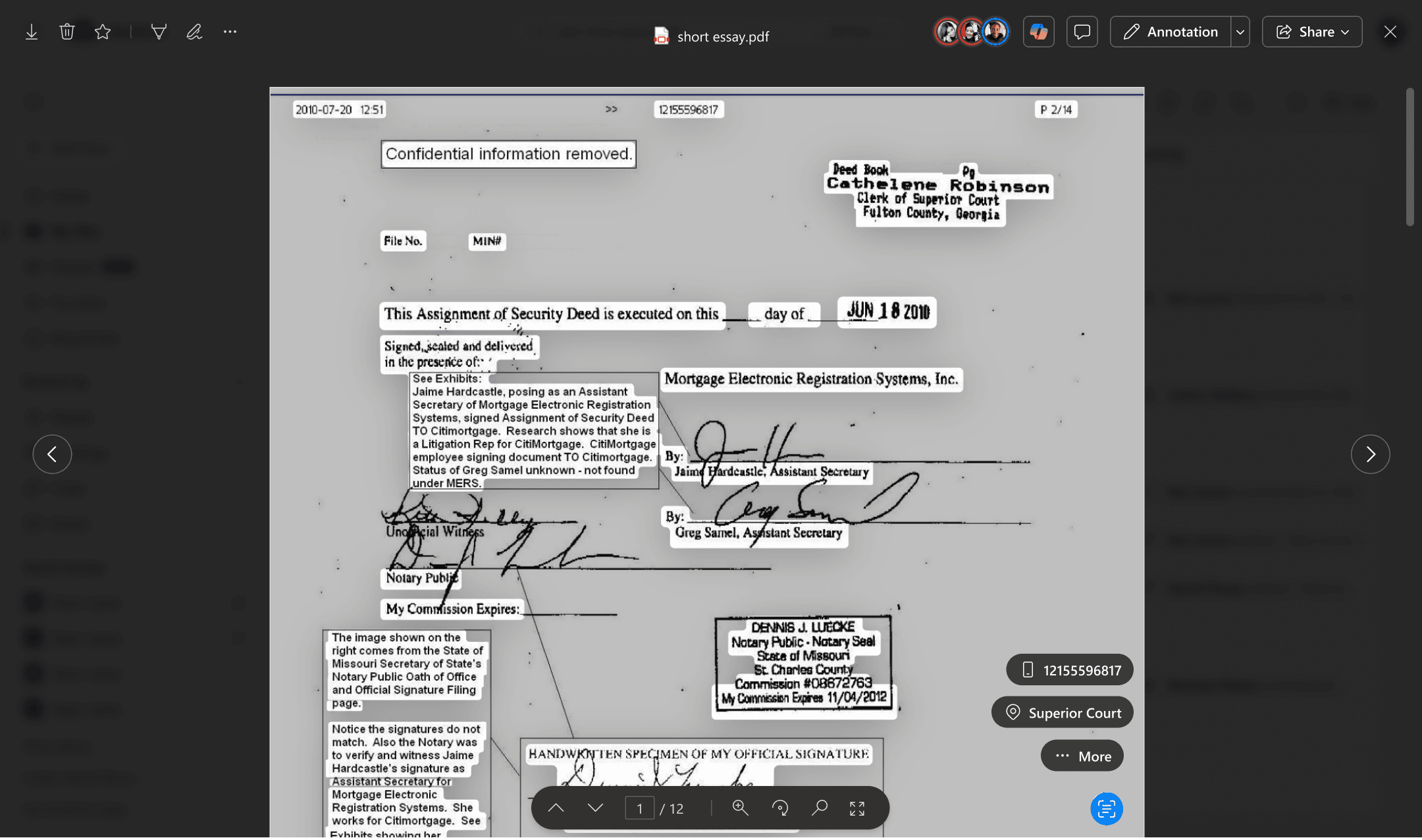
It’s estimated that scanned PDFs account for about 20% in ODSP today. Customers struggle with non-searchable PDFs, as evidenced by processing 1.1 million multi-page image files in private preview tenants. This highlights the critical need for effective OCR solutions.
DESIGN GOAL
Enabling seamless interaction with scanned PDFs and enhancing user productivity
Intuitive: Highlight user-centric interactions and let users instantly grasp how to extract text without tutorials
Accurate: addresses users fears of errors by emphasizing precision(multilingual support, error recovery)
Further actions: Light consumption experience such as copy recognized text.
BUSINESS GOAL
Access PDF content to unblock AI capabilities
We use OCR in the service of unlocking OneDrive Copilot features while interacting with scanned PDFs in canvas. Our goal is to expand the Copilot portfolio and increase usage among licensed users without delving deeply into COGS or business model consideration.
The Vision vs. Reality Dance
North start vision, dream seems unattainable
I started from the ideal:
Extract text
When users open a PDF file, text is automatically recognized via OCR. As the cursor hovers over text, it transforms into an I-beam pointer. Upon text selection, a contextual menu appears enabling actions like copy, search, or translation on the selected content.

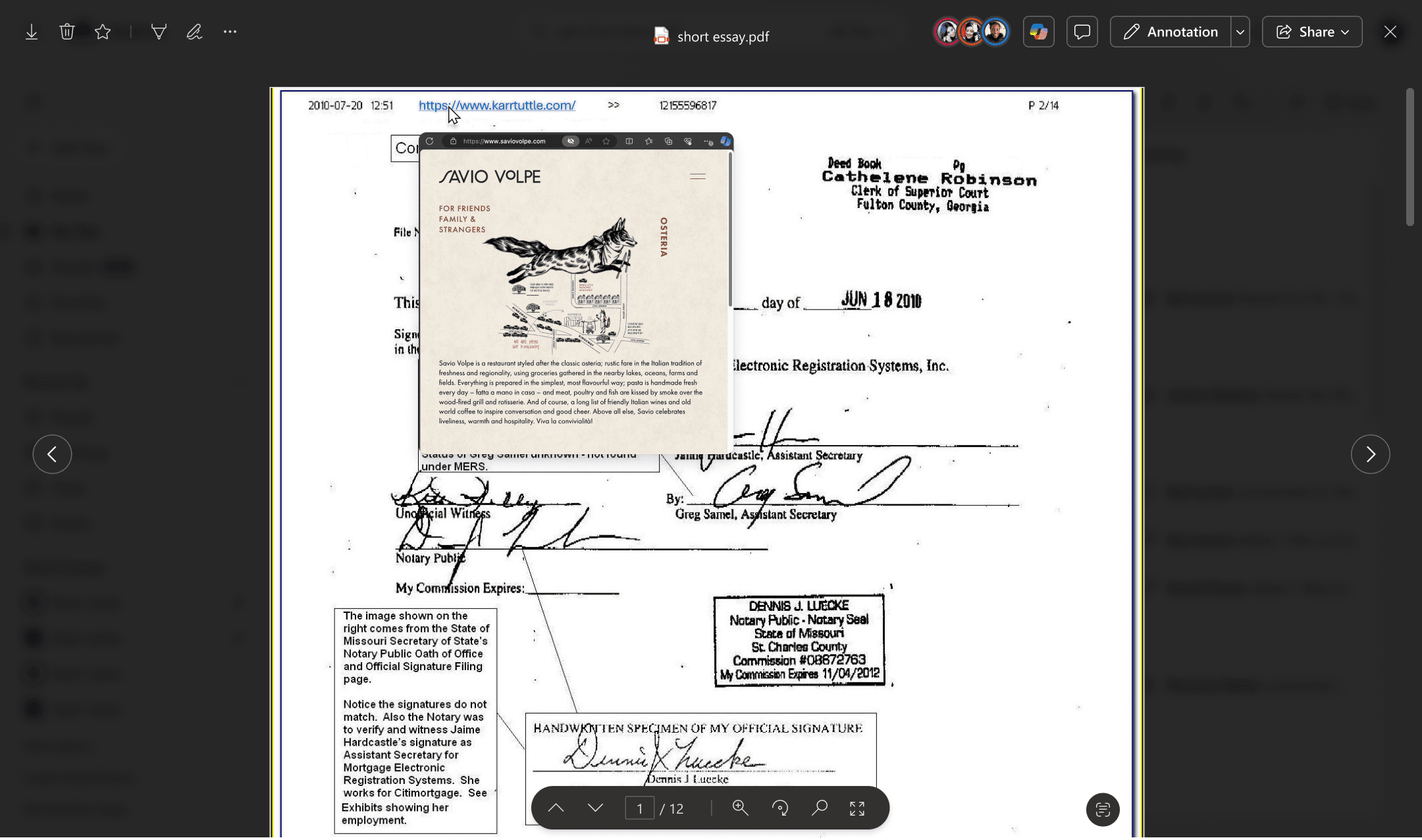
Open link
When users hover on a link, a contextual website preview renders directly below it.
Suggestions
Clicking the suggestion button in a file's lower-right corner surfaces contextual actions above it. Users can instantly interact—e.g., tap Email to message collaborators without leaving the context.
MVP
Our engineers flagged three challenge:
Auto-language detection doubled server load
Real-time extraction wasn’t scalable with existing APIs
No time for open link and suggestions
How I Adapted:
Added a discreet language dropdown during file selection.
Added a processing bar to inform users the scanned file is extracting
Put open link and suggestion in the next semester
Challenge 1
Choose language
When users left-click, right-click, double-click, or drag, the OCR menu will be activated. Meanwhile, users can select the target language before running OCR.
Challenge 2
Processing bar
When users choose to run OCR, an OCR processing progress bar will appear.
The Breakthrough
“How do we handle multi-language files? Or if the user selects French but it’s Spanish?”
Initial Assumption
We’d need complex multi-language support (weeks of work).
But…I redefined the problem
The problem wasn’t technical—it was about avoiding dead ends. Users needed a way to recover, not perfection.
Add an entrypoint:
Post-OCR language switcher
After users complete OCR, a language selection entry will be provided.
